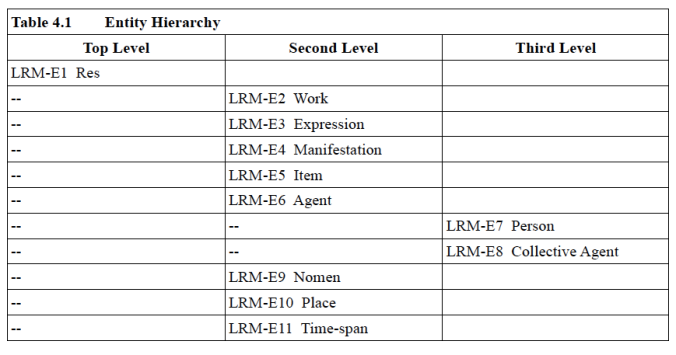
One of the higher level entities is “nomen” which was first seen in FRSAD. The term means “name” in Latin (there’s nothing friendlier to a modern audience than using Latin terms!). Nomen is s subclass of “Res” (Latin for “thing”). Here’s how they are defined:
“Res includes both material or physical things and conceptual objects. Everything considered relevant to the bibliographic universe, the universe of discourse in this case, is included. Res is a superclass of all the other entities that are explicitly defined, as well as of any other entities not specifically labeled.”
If you have experience with OWL you will recognize that Res is very similar to owl:Thing, which is defined: “Every individual in the OWL world is a member of the class owl:Thing. Thus each user-defined class is implicitly a subclass of owl:Thing.” owl:Thing also includes physical and conceptual objects; in fact, it includes everything that is not owl:Nothing.
Nomen, is an entity at the same logical level as Work, Expression, etc., and Person. All are subclasses of Res. Nomen is defined as “Whatever appellation is used to refer to any entity found in the bibliographic universe.” Then it goes on to say:
“Depending on the context of use, the same sequence of symbols can be assigned as a nomen of different entities in the real world even within the same language (polysemy and homonymy). Conversely, the same entity can be referred to by any number of nomens (synonymy). The association of nomens to entities is in general many-to-many.” (p. 20)
We recognize this as the ambiguity of natural language that humans navigate rather well in real life, but that causes us great problems when we need greater precision. Because machines do not have the intelligence to work within the complex information context that humans occupy, we resort to the creation of unambiguous identifiers to solve the precision problem.
However, FRBR-LRM considers identifiers to also be nomen, and this is in contradiction to to the concept of and use of identifiers in any community that I have encountered. By considering that identifiers, as nomens, can be many-to-many the LRM eliminates any notion of unique identification, making functioning with data to be essentially logically impossible. As examples of identifiers as nomen they use an ISBN and an ISNI. Here’s what ISNI.org says about the role of its identifiers:
“The mission of the ISNI International Authority (ISNI-IA) is to assign to the public name(s) of a researcher, inventor, writer, artist, performer, publisher, etc. a persistent unique identifying number in order to resolve the problem of name ambiguity in search and discovery…” (emphasis in original)
“Unique” – that’s the key. Identifiers are identifiers because they are unique. Mixing unique identifiers and non-unique names in a single entity ignores the vital importance of identifiers. Names can vary; you can have full names, short names, nicknames, terms in various languages – all of those are names and we accept that, while they communicate to human beings are do not carry the precision needed for data processing. Identifiers must identify, something that names do not do. Names and identifiers are not the same thing. Period.
Oh, and the irony is that they have assigned unique identifiers to the LRM entities. Why? “Every element in the model is numbered for unambiguous reference.” (p.11)